When it comes to building AI-first platforms, asking which is the best AI is the wrong question. In a landscape where models constantly leapfrog each other, what really matters is architecture: can you evaluate and swap models, even at the subtask level, as they evolve? We built FAIT with that flexibility from day one—and leveraged it to evaluate Anthropic’s Claude Sonnet 3.5 v2 and 3.7, OpenAI’s GPT-4o, and DeepSeek-V3 through FADM-1, our AI-Driven Integration (ADI) benchmark. Claude leads overall. But DeepSeek shows surprising strength in transformation logic—often outperforming GPT-4o on this key subtask. But the real takeaway isn’t which AI performed best—it’s that this is the wrong question to ask when winners keep changing. The only strategy that scales is being ready before they do.
The Wrong Question—And the Right Strategy
“Which model is the best?”
As an AI-first SaaS company, it’s one of the most common questions we get at FAIT.
Asking which is the best AI is a fair question—but it’s the wrong one.
When you’re building production-grade, AI-first applications—especially in fast-evolving domains like AI-Driven Integration (ADI)—the more important questions are: How easily can you switch between models at runtime? How do you choose the right model for each subtask, not just the whole workflow? And what happens when a model goes down, spikes in cost, or simply gets outpaced in the next release cycle?
“The right model depends on the task—and that changes fast.”
Just in the last few months, Claude 3.7, DeepSeek-R1, and others have reshaped the leaderboard in different ways—and new contenders seem to arrive every week. Some models excel at analytical reasoning. Others are tuned for conversational safety. Some are fast and cheap but shallow; others are slower and more thorough. Some handle PDFs natively. Others don’t. The right model depends on the task—and that changes fast.
Amid this rapid change, it’s no wonder that we’ve seen top commercial AIs go offline for hours—a sharp reminder that asking which AI performs best is the wrong question when resilience matters just as much.
The Model Is Not the Strategy
And that raises an important point—our strategy doesn’t begin with building models from scratch. Given the pace of innovation and the billions backing today’s leading LLMs, it’s far more effective to harness the best of what’s already available. Thus, with the right engineering, orchestration, and design patterns layered on top, today’s commercial and open-source foundation models already deliver transformative results.
To put it another way, Andrew Ng famously said, “AI is the new electricity.” If that’s true, then model providers like OpenAI, Anthropic, and DeepSeek are like the electrical power grid—delivering raw power through massive, ever-improving foundation models. Their consumer-facing tools, like ChatGPT and Claude, are like basic lightbulbs: general-purpose applications that light up when plugged in.
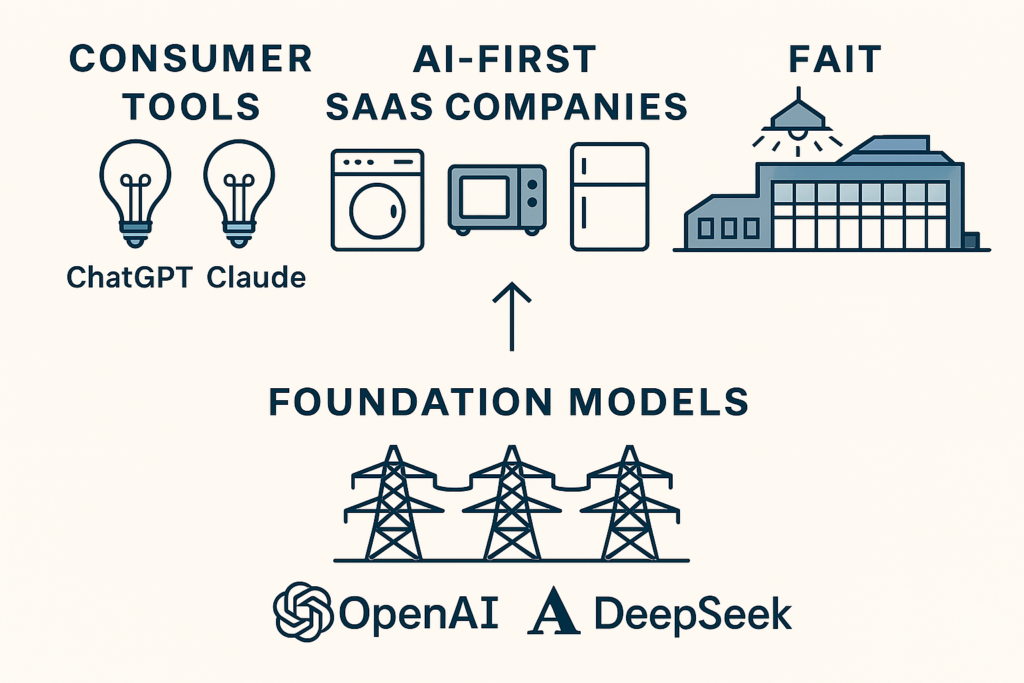
In this case, that makes AI-first SaaS companies the appliance manufacturers—the ones designing how that power gets used. Some build simple tools; others engineer advanced, adaptive systems. At FAIT, we’re focused on the industrial end of that spectrum: applying model power with precision, control, and resilience. Continuing the analogy, think of our platform as a smart industrial lighting system for AI-Driven Integration—built not just to shine, but to orchestrate how, where, and when light is applied across a complex enterprise factory floor.
In that kind of environment, staying model-agnostic isn’t just smart—it’s essential.
From Strategy to Standard: Architecting Model Agility
Designing for Cognitive Granularity
Before you can choose the right model for each subtask, you need to understand the nature of the task itself. For us, that task is AI-Driven Integration (ADI)—a broad domain spanning everything from enterprise data architecture and mapping to validation, reconciliation, and governance. Our flagship component, FAIT Analyze, zeroes in on one of the most critical pieces: AI-Driven Mapping (ADM). Specifically, it automates the business analysis that interprets and translates meaning between source and target systems.
ADM isn’t just about schema alignment—it’s about semantic translation. Traditionally, human analysts would spend weeks—sometimes months—combing through spreadsheets, PDFs, and systems specs, writing logic by hand and validating every edge case. It’s a slow, expensive, and often inconsistent process. At FAIT, we broke this into a repeatable series of reasoning steps. Each of those steps maps to a model-level decision point—moments in the pipeline where different models can be chosen based on their strengths. That’s where architectural flexibility delivers real performance gains.
Our FAIT Analyze pipeline includes eight key decision points where specific models can be selected:
- Process source references
- Process target references
- Filter irrelevant targets
- Generate mapping logic & rationale
- Validate mapping logic
- Generate transformation code
- Refine logic via AI interaction
- Test logic on sample data
Our decision point architecture gives us the ability to match the right model to the right step, rather than forcing a single model to handle the entire pipeline. And those models behave differently: Claude is conservative and cautious. GPT-4o is fluent but literal. DeepSeek is erratic—but occasionally brilliant. That’s exactly why asking for the best AI is often the wrong question—and why subtask-level flexibility delivers real performance gains.
The Architecture of Abstraction
To make that possible, we built a generalized model abstraction layer that standardizes how our platform interacts with LLMs. Behind the scenes, that means decoupling prompts, outputs, and validation logic from any one model provider’s quirks or APIs. We also integrate guardrails and confidence checks throughout, catching low-confidence outputs before they cascade into errors. We validate structured outputs against internal schemas, allowing for consistency and quality regardless of the underlying model.

This design lets us orchestrate subtasks through a clean interface—without rewriting logic every time the underlying model changes. It’s complex engineering, but it enables seamless model swapping, resilient fallback strategies, and ongoing optimization. That flexibility lets FAIT deliver mapping results 400x faster than a human analyst, with 80–90% accuracy on real-world tasks. But when your platform depends on only one model, disruptions can cause those gains to disappear overnight. That’s why model agility isn’t just a performance feature—it’s a survival trait.
That’s our current operational baseline. But to push further, we need a way to measure…
Turning Strategy into Score: Introducing FADM-1
To systematically measure model performance, we created FADM-1—the first public benchmark to evaluate LLMs on real-world industrial use cases in enterprise systems integration, starting with AI-Driven Mapping (ADM). By aligning to benchmark best practices—clarity, measurability, fairness, and extensibility—FADM-1 establishes a strong foundation for evaluating real-world ADM performance.
Clarity
FADM-1 simulates a real-world integration scenario: mapping data from an HR source system to a government reporting target system. The inputs include structured CSVs and semi-structured PDFs; in order to produce meaningful mapping output, the AI must:
- Identify relevant source fields
- Interpret target field requirements
- Generate transformation logic
- Provide reasoning commentary
- Handle gaps and partial mappings
- Self-report mapping status and confidence
Measurability
Each model’s output is compared against a human-created golden source mapping, with results scored across six sub-metrics. But not all metrics are equal. FADM-1 places 70% of the total weight on transformation logic—the most complex and high-value part of the mapping process, and the hardest for models to get right. Source and target recognition are each weighted at 10%, while status and confidence each contribute 5%. Commentary is captured and scored, but not currently included in the final score.
Fairness
Scoring blends exact-match rules, semantic similarity, and domain-specific validation. We structure outputs as JSON and build in guardrails to ensure syntactic and referential integrity—for example, verifying that source fields used in logic actually exist. The benchmark infrastructure is agnostic to individual models, and no postprocessing is required to align formats. To account for differences in model capabilities—such as native PDF processing—we setup multiple versions of each scenario where applicable. For example, models with native PDF support (like Claude) were tested both with and without that feature enabled, ensuring results reflected real-world conditions while maintaining a level playing field.
Extensibility
FADM-1 isn’t just a one-off test—it’s a repeatable, extensible benchmark. Because the evaluation framework is scenario-agnostic, we can add new test cases simply by registering a new pair of source/target reference documents and a corresponding golden mapping. That makes FADM-1 adaptable across domains, formats, and levels of complexity—laying the groundwork for FADM-2, which will introduce measurement of XML addressing, logic chaining, ambiguity resolution, and new metrics like latency and token cost.
By turning our model strategy into a measurable score, we can track progress, compare models, and—most importantly—keep improving. Because model agility isn’t just about flexibility. It’s about performance, at scale.
Not All Intelligence Is Created Equal: What FADM-1 Reveals
Here’s how the models performed across all metrics:
| Model | Target Labels | Source Fields | Transform Logic | Status | Confidence | Commentary | Final Score |
|---|---|---|---|---|---|---|---|
| Claude 3.5 (w/ PDF) | 100 | 100 | 86.16 | 88.89 | 72.22 | 88.17 | 88.37 |
| Claude 3.5 (No PDF) | 100 | 91.11 | 84.44 | 97.78 | 72.22 | 83.56 | 86.72 |
| Claude 3.7 (w/ PDF) | 100 | 100 | 83.65 | 88.89 | 71.67 | 78.00 | 86.58 |
| Claude 3.7 (No PDF) | 100 | 100 | 81.51 | 88.89 | 71.11 | 81.33 | 85.06 |
| DeepSeek V3 | 100 | 100 | 77.08 | 88.89 | 72.22 | 78.00 | 82.01 |
| OpenAI GPT-4o | 100 | 100 | 72.87 | 88.89 | 72.22 | 87.78 | 79.07 |
Note: “(w/ PDF)” indicates the model was provided the original PDF file directly (native support). “(No PDF)” means the PDF content was first converted to plain text.
Why Performance Diverged: What the Scores Didn’t Show
Claude 3.5 with native PDF processing outperformed all other models across nearly every sub-metric, especially in transformation logic and commentary. Even when leveling the playing field by removing native PDF support, Claude 3.5 maintained strong performance, underscoring its internal consistency and reasoning capabilities.
Claude 3.7 was slightly less accurate, despite identical scores in source and target schema recognition. Commentary and transformation accuracy dipped slightly, suggesting possible differences in model tuning.
DeepSeek exceeded expectations in logic generation, outperforming GPT-4o and nearly matching Claude 3.7 in key areas. However, it was less stable across runs, showing occasional fallback behavior.
GPT-4o delivered the lowest logic accuracy—despite strong commentary and perfect field recognition. It frequently omitted required business mapping rules, defaulting to literal passthrough logic.
Symbolic Reasoning in Action: Why Lookup Logic Separates the Leaders
As an example, one of the clearest indicators of integration intelligence emerged in the mapping for the Occupation target field.
In this scenario, the source system used the field Role, which stored short internal codes like "DEV", "TST", and "MGR". The target system, however, required full-form occupational titles like "Developer", "Tester", and "Manager"—from a fixed list of accepted values. This meant the AI needed to construct a symbolic lookup table, translating each internal code into the appropriate external label.
The golden source human mapping specified this transformation explicitly:
Lookup(
Role Occupation
DEV Developer
TST Tester
MGR Manager
)This is more than a simple copy or conditional—it’s a form of structured symbolic reasoning. The AI must infer that the Role field contains coded values, align those to the expected business labels, and express the mapping and transformation logic in a formal lookup structure.
Surprisingly, most models failed this task.
- Claude 3.5 (with PDF) consistently generated the correct mapping logic, including a valid lookup table with matching source-target pairs.
- Claude 3.5 (no PDF) performed almost as well, but occasionally defaulted to simplified or incomplete mappings.
- GPT-4o, despite its fluency, almost always defaulted to
output = #Role#, ignoring the need for translation entirely. - DeepSeek showed flashes of correct logic, but was inconsistent across runs.
To be sure, in the enterprise world, this isn’t a cosmetic error—mislabeling job roles, or any domain value for that matter, can trigger downstream reporting errors, regulatory violations, or automation failures. That’s why lookup logic is a high-signal test that we track closely in FADM-1—it separates models that understand schema from those that understand the business.
Beyond the Benchmark: What Comes Next
Getting to 80–90% accuracy didn’t come from prompting alone. It came from FAIT’s end-to-end architecture: a structured pipeline, an abstraction layer, and decision-level model control. But to move beyond that, we need to raise the bar—not just for models, but for the benchmarks that evaluate them.
FADM-2, our next benchmark iteration, will measure more demanding logic combinations, multi-layered field mappings, and hierarchical formats like XML. Models will need to generate transformation logic that combines formatting, conditionals, and lookups—sometimes within a single field.
“The best AI today may not be the best AI tomorrow…”
We’ll also scale up the benchmark scenarios: more fields, more diverse mappings, and broader coverage of commercial, open-source, and small-scale models. All will be tested under uniform conditions using FAIT’s abstraction layer.
But we’re not stopping at accuracy. FADM-2 will introduce new performance dimensions—latency, token cost, and code quality—measured alongside mapping fidelity.
Over time, we may explore lightweight fine-tuning—or even proprietary models trained on FAIT’s integration data. But for now, the most scalable strategy remains the one FADM-1 already proves:
Architectural agility beats model lock-in—every time.
It’s yet another reminder that chasing the best AI is the wrong question when the target keeps moving. In a world where models improve weekly, architectural agility will always outpace any single-model bet.
Thoughts on the results? Surprises? Suggestions for what you’d like to see in FADM-2? Do you agree that “the best AI?” is the wrong question? Share your thoughts in the comments.